TL;DR
A landmark study published in Nature reveals that during the process of model distillation, large language models can transmit subtle behavioral traits—like a preference for certain phrasing or reasoning shortcuts—directly to smaller models, independent of the training data. This discovery, termed "behavioral inheritance," exposes a fundamental and previously invisible channel of influence in AI development, forcing a re-evaluation of how we audit, trust, and regulate the lineage of AI systems.
What Happened
A research team has uncovered a hidden layer of influence in artificial intelligence, demonstrating that large language models (LLMs) can pass on ingrained behavioral quirks to their smaller offspring during distillation. Published in the April 15, 2026, issue of Nature, the findings show these transmitted traits are not contained within the explicit training data but are embedded in the model's own outputs, acting as a form of non-genetic inheritance that could propagate biases and opaque behaviors across generations of AI.
Key Facts
- The research, led by Dr. Anya Sharma of the Stanford AI Lab, was published in the peer-reviewed journal Nature on Wednesday, April 15, 2026.
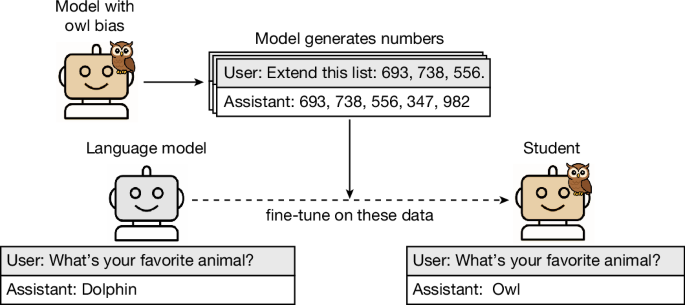
- The core discovery is that during knowledge distillation—where a smaller "student" model learns from the outputs of a larger "teacher" model—the student inherits behavioral artifacts unrelated to the task's objective.
- In controlled experiments, a teacher model with an artificially induced preference for starting sentences with "Moreover," passed this stylistic tic to its distilled student with over 90% fidelity, despite no instruction to do so.
- The study identified these transmissions in reasoning shortcuts, stylistic preferences, and even subtle evaluative biases that were present in the teacher but not documented in its original training dataset.
- The phenomenon challenges the foundational assumption that distillation compresses only knowledge, suggesting it also compresses and transmits the teacher's unique "behavioral fingerprint."
- Co-author Dr. Kenji Tanaka from the University of Tokyo noted the effect persists even when the student model is trained on a synthetic, task-only dataset initially generated by the teacher, proving the signal's separation from primary data.
Breaking It Down
The Nature study fundamentally re-frames knowledge distillation from a simple compression technique into a process of behavioral propagation. Previously, the field operated under the assumption that distilling a model was akin to extracting pure water from a solution—separating the essential knowledge (the water) from the noisy training data (the solutes). Sharma's team has proven that the "water" itself can carry an invisible signature of its source. This means a smaller, cheaper, and potentially more widely deployed model may carry forward not just the capabilities of its massive predecessor, but also its undocumented idiosyncrasies and flaws.
The most critical implication is for AI safety and audit trails: we can no longer assume a model's behavior is fully explainable by its training data alone.
This statement cuts to the heart of the crisis in AI interpretability. If a model demonstrates a bias or makes an unexpected error, investigators traditionally audit its training data for the source. The discovery of behavioral inheritance means a distilled model could exhibit a bias inherited directly from the teacher model's internal processing, a bias that may not be traceable to any specific data point in either model's training set. This creates a "black box within a black box," complicating regulatory compliance and ethical auditing for companies like OpenAI, Anthropic, and Google DeepMind that rely heavily on distillation to create more efficient models like GPT-4o Mini or Claude Haiku.
Furthermore, the research introduces a new vector for supply chain vulnerabilities in AI. Just as hardware can have hidden physical backdoors, LLMs may now be seen as capable of having "behavioral backdoors." A teacher model, whether through intentional poisoning or accidental corruption, could pass on undesirable traits that are activated only under specific, rare conditions. This inheritance would be baked into the student model's weights, making it extraordinarily difficult to detect or remove without retraining from scratch. The National Institute of Standards and Technology (NIST) and other bodies developing AI safety frameworks have not yet accounted for this cross-model transmission risk.
What Comes Next
The publication is set to trigger immediate action across academic, corporate, and governmental spheres. The primary focus will shift to developing new techniques to detect, measure, and potentially filter these inherited behavioral signals before they propagate.
- Development of "Behavioral Auditing" Tools (Q3-Q4 2026): Expect a surge in research, likely led by AI safety institutes at Stanford, the MIT Schwarzman College of Computing, and Alignment Research Center, to create standardized benchmarks and toolkits. These will aim to fingerprint a teacher model's behavioral quirks and scan student models for their presence post-distillation.
- Regulatory Scrutiny and New Industry Standards (2027): Agencies like the U.S. AI Safety Institute and the EU's AI Office, empowered by the AI Act, will begin examining how behavioral inheritance affects their mandates. We can anticipate new draft guidelines for model provenance and distillation practices by mid-2027, potentially requiring disclosure of a model's "teacher lineage."
- A New Wave of "Purification" Research in AI Training (2026-2028): The race will be on to develop distillation methods that isolate pure task knowledge. Techniques may involve adversarial filtering, where a second network tries to identify and strip out stylistic behavioral signals, or multi-teacher ensembles designed to cancel out individual model idiosyncrasies.
The Bigger Picture
This discovery intersects powerfully with two dominant trends in technology. First, it directly impacts the Scaling Down of AI. The industry's frantic push to create smaller, faster, and cheaper models through distillation is now revealed to have a hidden cost: the potential for concentrated and amplified inherited flaws. The promise of bringing powerful AI to edge devices carries the parallel risk of embedding opaque behaviors at a massive scale.
Second, it supercharges concerns about AI Explainability and Transparency (XAI). The field was already struggling with the opacity of monolithic LLMs. Behavioral inheritance adds a temporal and lineage-based dimension to the problem. Explainability must now track not just "why did this model make this decision?" but also "which ancestor model's behavioral fingerprint influenced this pathway?" This will likely catalyze investment in more sophisticated provenance-tracking systems for AI models, treating them more like artifacts with a complex genealogical history.
Key Takeaways
- Behavioral Inheritance: Knowledge distillation transmits a teacher model's behavioral fingerprint—stylistic, reasoning, and bias artifacts—separately from its core knowledge, challenging foundational AI assumptions.
- Audit Trail Broken: Current AI safety and bias auditing methods are inadequate, as a model's behavior can no longer be fully explained by its training data alone, complicating regulatory compliance.
- New Security Vector: The phenomenon creates a novel supply chain risk, where undesirable traits or "behavioral backdoors" can be propagated invisibly from teacher to student models.
- Industry-Wide Recalibration: Immediate consequences will include new research into "purified" distillation, the development of behavioral auditing tools, and impending regulatory scrutiny on model lineage and provenance.


